



1. 模型介绍
Stable Diffusion XL版模型是由Stability AI研发并开源的文生图大模型,创意图像生成能力行业领先。指令理解能力强,支持反向Prompt定义不希望生成的内容。百度智能云千帆平台对图像安全能力进行了全面增强。
2. 应用场景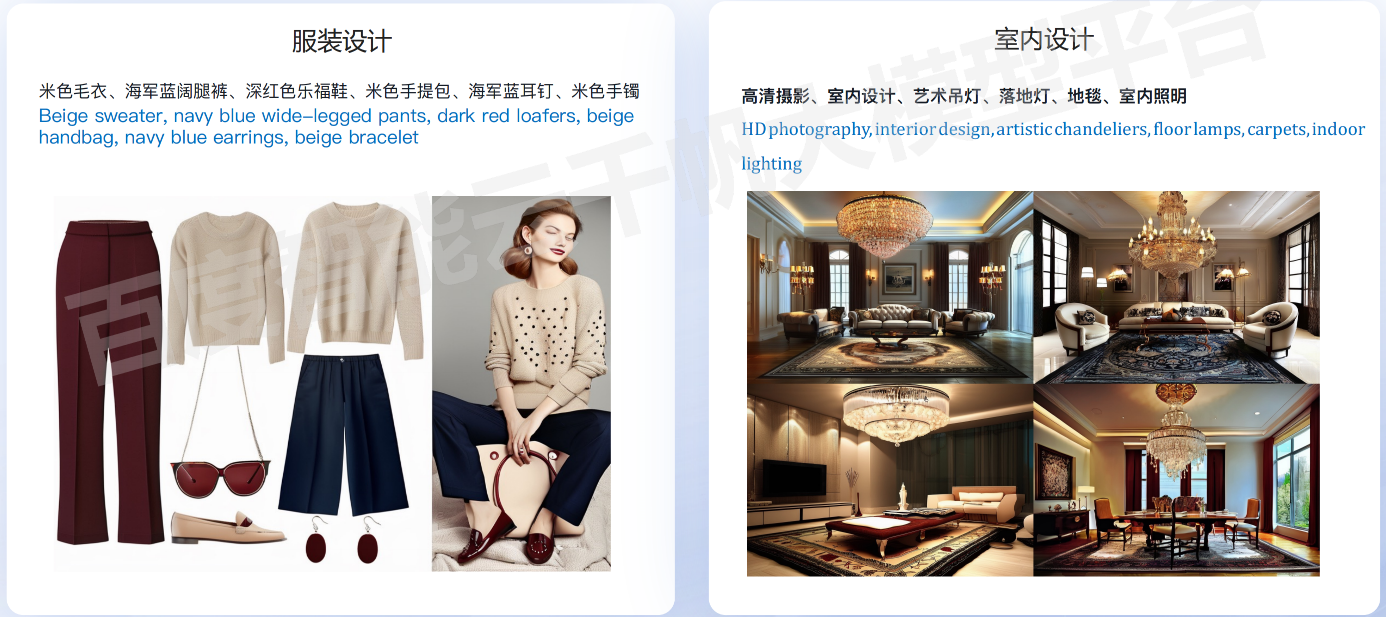

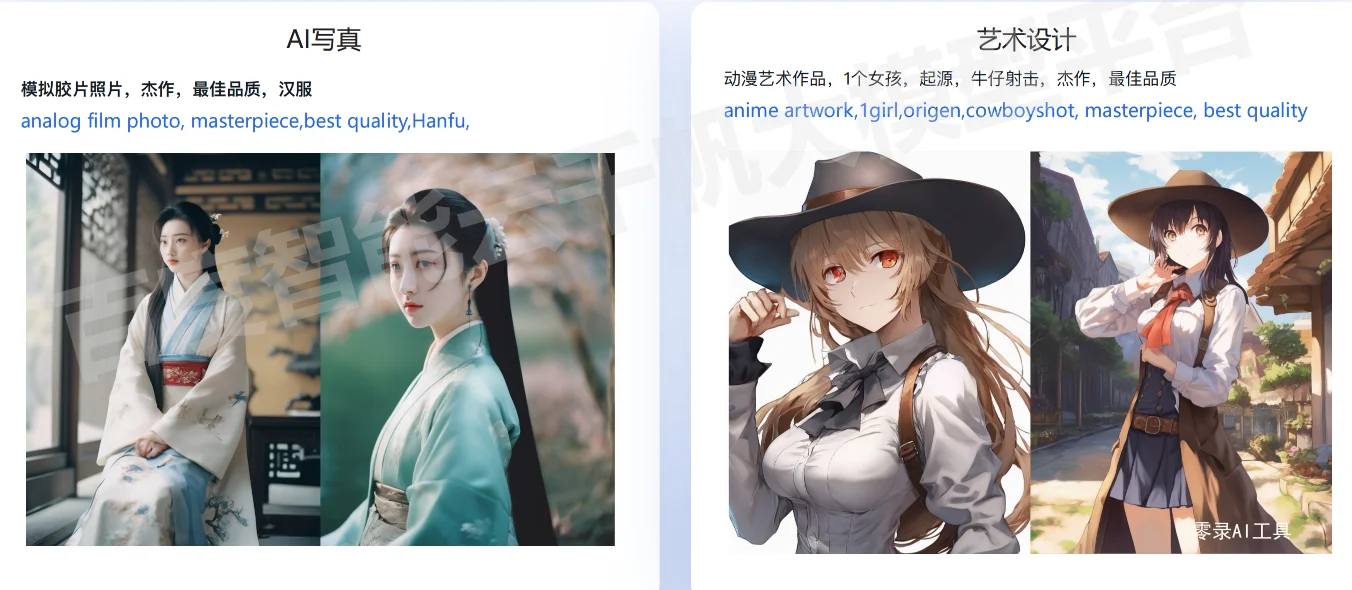
模型局限性说明
模型可能无法达到照片的真实感。
模型可能无法绘制清晰的文本。
模型可能会在涉及复合性的难度程度高的任务上可能遇到瓶颈,例如渲染一张与“蓝色球体上方的红色立方体”相对应的图像。
通常情况下,面部和人可能无法正确生成。
3. 评测效果
Stable Diffusion 基于Google Research PartiPrompts (P2) 评测集,超过1600条评测英文Prompt,包括了不同场景和复杂度的Prompt;总体来说有如下优势:
日常物品绘图能力领先,整体能力达到SOTA水平
理解力强,创意十足,可以生成丰富多样的图像细节
Prompt指令调整空间大,支持模型定制(LoRA),适合高级开发者使用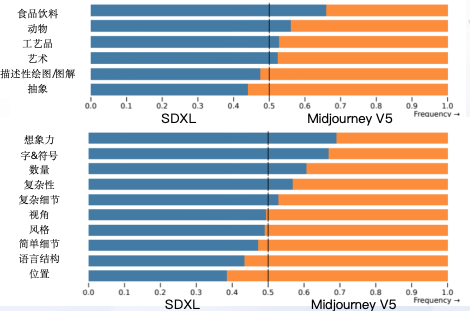
相较于 SDXL 0.9、 Stable Diffusion 1.5/2.1,SDXL模型也有更好的表现: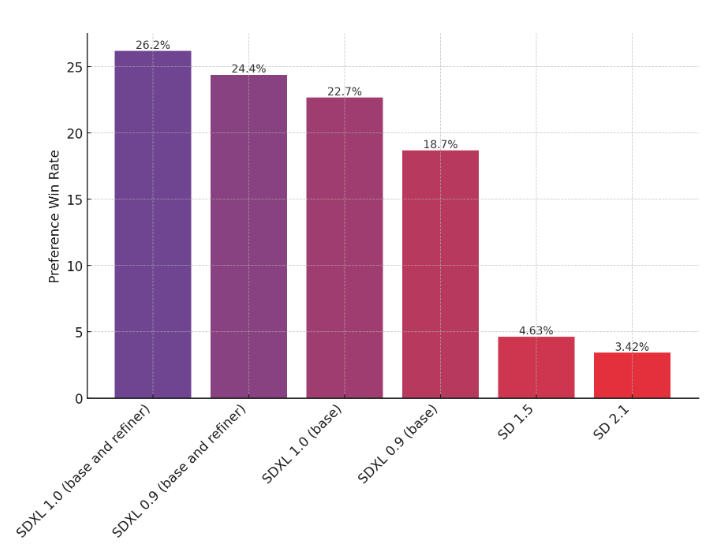
评测数据集样本分布如下,了解详情:https://github.com/google-research/parti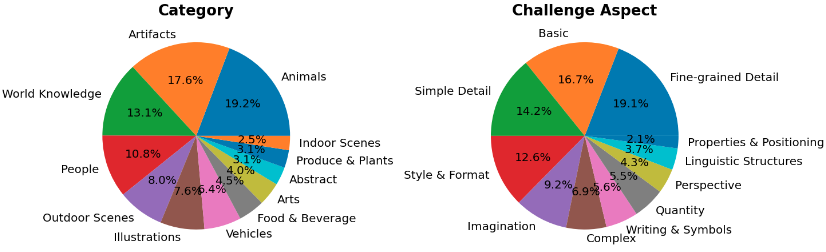
4. 技术亮点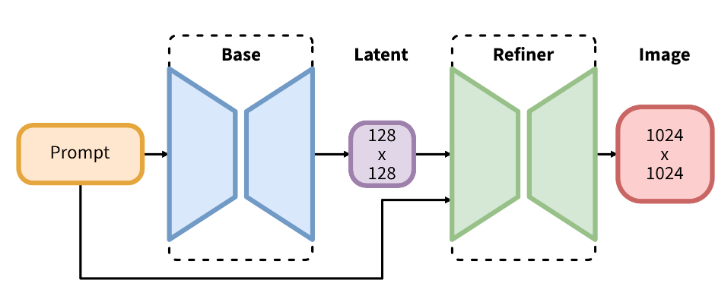
SDXL consists of an ensemble of experts pipeline for latent diffusion: In a first step, the base model is used to generate (noisy) latents, which are then further processed with a refinement model (available here: https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/) specialized for the final denoising steps. Note that the base model can be used as a standalone module.
SDXL包含了一系列扩散模型的组合:第一步使用基础模型生成(有噪声的)图像,然后使用专门用于最终去噪步骤的Refiner模型来进行图像优化。
Alternatively, we can use a two-stage pipeline as follows: First, the base model is used to generate latents of the desired output size. In the second step, we use a specialized high-resolution model and apply a technique called SDEdit (https://arxiv.org/abs/2108.01073, also known as "img2img") to the latents generated in the first step, using the same prompt. This technique is slightly slower than the first one, as it requires more function evaluations.
或者我们也可以使用一个两阶段的方法:首先,使用基础模型生成所需输出大小的潜在图像。第二步,我们使用专门的高分辨率模型,并使用称为SDEdit(https://arxiv.org/abs/2108.01073,也称为“img2img”)的技术,用相同的提示词对第一步生成的图像优化。这种方法比第一种方法稍慢。
5. 相关资源
千帆预置丰富的文生图 Prompt 模板(左侧导航栏进入Prompt工程 - Prompt模板)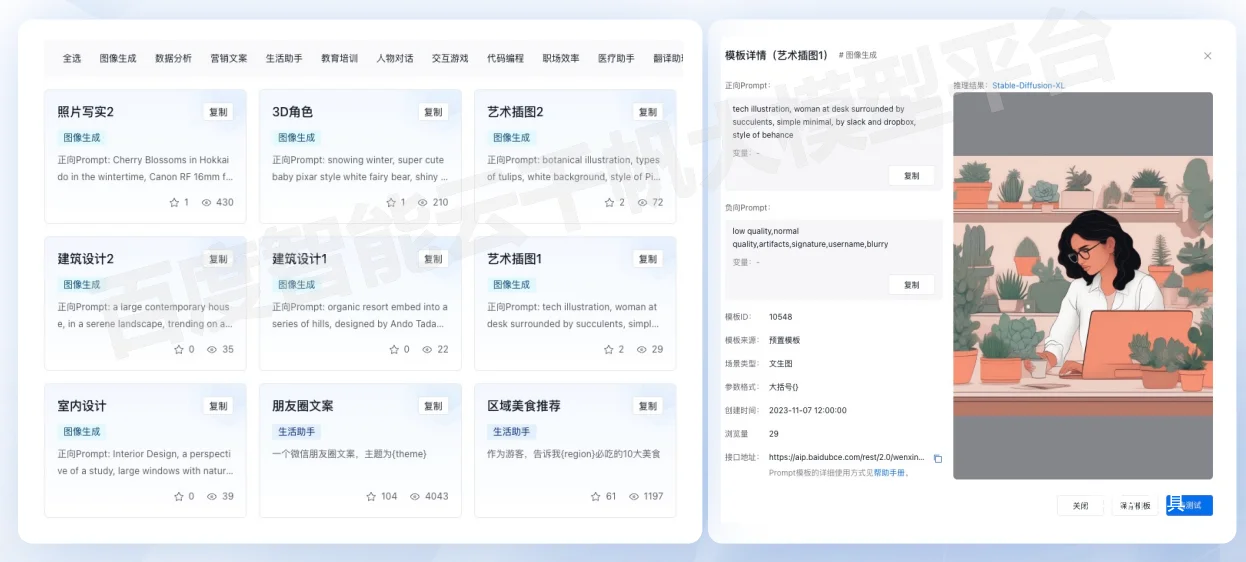
Stable Diffusion 代码库:https://github.com/Stability-AI/generative-models
Stable Diffusion 官方示例:https://clipdrop.co/stable-diffusion